La collaboration au service de la création numérique
L’éclatement de la bulle internet spéculative en mars 2000 a cassé la notoriété du web et la confiance du grand public face aux nouvelles technologies. La communauté de développeurs a repris la main avec le web 2.0 (démocratisation de l’accès, échange & partage des connaissances). L’intercommunication des utilisateurs sur le réseau planétaire a permis de créer un environnement de travail plus ouvert. Bien que le principe d’ouverture des connaissances soit né au milieu des années 80 dans l’informatique avec Richard Stallman, il ne s’est répandu qu’à partir des années 2000 avec ce web collaboratif, notamment grâce aux forums et aux premiers réseaux (MySpace, Facebook, Reddit, Wikipédia…). Les développeurs se sont retrouvés pour créer en commun.
Cette collaboration a vu naître des outils que nous utilisons quotidiennement sans le savoir. Les serveurs pour le web Nginx et Apache représentent plus de 60% des parts du marché, le SGBD MySQL et le CMS WordPress plus de 40%. Quel est le point commun entre ces technologies ? Il s’agit de logiciels Open Source.
Est-ce uniquement grâce à une plus grande facilité des échanges entre les développeurs que le web a pu évoluer ? Il s’agirait plutôt d’une plus grande liberté de création grâce aux principes de logiciel libre et Open Source.
1. La création sans restriction de droits
Les projets collaboratifs vivent grâce aux différentes contributions des développeurs. Ces derniers sont formés en communautés, majoritairement virtuelles. Bien qu’elles n’ont aucune “proximité géographique [ou] organisationnelle”², elles arrivent à coopérer et produire un programme informatique commun. Ces communautés ne sont pas soumises à des relations “marchande [ou] d’autorité” mais sont guidées par “l’accumulation [et] l’échange de connaissances”.
Il existe deux courants dans l’informatique dite libre : le logiciel libre (free software) et l’open source. Le premier se fonde sur 4 piliers pour l’exploitation d’un programme : l’utilisation, la modification, la copie et la redistribution. C’est ce qu’on appelle la licence GPL. Par exemple, un programme, soumis à cette licence et qui a été modifié par un développeur, devra être redistribué avec les mêmes règles à la communauté. On retrouve ce principe avec le matériel libre qui se concentre sur du matériel physique comme le microcontrôleur Arduino. D’un autre côté, l’open source donne la possibilité d’utiliser et de modifier le code d’un programme sans avoir besoin de le partager à l’identique. Ce principe s’applique à toute création faite. Le mouvement du libre ne signifie pas que le créateur d’une œuvre ne souhaite pas la protéger avec un cadre légal. Le “libre” revendique uniquement “le droit pour tous à un accès libre au savoir, quelle que soit sa nature (créations, informations)”. Les licences imposent une forme “d’exploitation et de redistribution des contenus”. Le monde informatique n’aurait pas pu évoluer et devenir comme nous le connaissons aujourd’hui sans ce mouvement (non freiné par le droit d’auteur).
En effet, le web tourne principalement grâce aux logiciels libres et open source. Nous citions Apache ou MySQL mais on peut compter aussi les principaux frameworks JavaScript comme React et Angular ou encore CSS comme Bootstrap. Ces outils ont initialement et respectivement été développés par Facebook, Google et Twitter. On peut s’interroger de l’intérêt qu’ont les GAFA à publier le code source de certains de leurs produits sans contrepartie financière (issue de la vente par exemple). Si le code source est publié et disponible, il pourra être étudié par tous. Par conséquent, la communauté de développeurs pourra, de manière bénévole, améliorer le produit et corriger les éventuelles failles de sécurité. Certaines entreprises créent leur propre licence, entre partage et restriction du code, afin d’en contrôler l’ouverture et les utilisations faites. Les grandes entreprises “mutualisent des programmes de recherche et développement […] et contribuent en commun à l’écriture du code”. On a des codeurs bénévoles qui partagent leurs contributions entre les périodes de “travail et loisir” car ils y trouvent leur compte (“amusement, apprentissage, reconnaissance”). Les membres d’une communauté partagent la même pratique du code. Ils résolvent un “problème en comptant qu’à chaque nouveau problème rencontré, il sera partagé et résolu par d’autres [de ses] membres”.
Cet “acte de donner sans contrepartie” n’est pas sans “désintéressement”. De manière informelle, il y a toujours un “contre-don”, c’est-à-dire un “renvoi à l’autre” de l’aide qui nous a été apportée. Ce principe tire ses origines du monde universitaire des débuts d’Internet. Les chercheurs étaient plutôt motivés par l’envie de partager leurs connaissances que de les vendre. Ces valeurs représentent encore le profil type d’un développeur. Qui n’a pas été aidé, lors d’un bug dans son programme informatique, par une réponse d’un autre développeur sur le forum Stackoverflow ? Cette entraide ponctue le quotidien d’un codeur (aussi bien junior que senior !). C’est ce que l’on appelle “l’esprit de développeur”. Cette culture de collaboration et de partage se retrouve parmi nos étudiants en filière Numérique au Campus. En projet de groupe ou en individuel, les apprentis du DNMADe Numérique ou du Bachelor Chef de Projet Web partagent ces valeurs et sont plus efficaces dans leur travail. Nous enseignons également l’utilisation et la production à travers ces outils libres, tel que le CMS WordPress. Les étudiants apprennent à administrer un site de A à Z et à créer leur propre thème WP. Par ailleurs, pour leurs projets, ils n’utilisent pas uniquement des programmes libres mais aussi des données ouvertes.
Bibliographie :
-
Selon www.slintel.com
-
CORIS Marie, LUNG Yannick, Les communautés virtuelles : la coordination sans proximité ? Les fondements de la coopération au sein des communautés du logiciel libre, Revue d’Économie Régionale & Urbaine, 2005
-
BROCA Sébastien, Utopie du logiciel libre. Du bricolage informatique à la réinvention sociale, Le Passager clandestin, 2013
-
OLIVIERI Nicolas, Logiciel libre et open source : une culture du don technologique, Quaderni, 2011
-
BROCA Sébastien, Utopie du logiciel libre. Du bricolage informatique à la réinvention sociale, Le Passager clandestin, 2013
-
CORIS Marie, LUNG Yannick, Les communautés virtuelles : la coordination sans proximité ? Les fondements de la coopération au sein des communautés du logiciel libre, Revue d’Économie Régionale & Urbaine, 2005, p. 397-420
-
OLIVIERI Nicolas, Logiciel libre et open source : une culture du don technologique, Quaderni, 2011
-
PENARD Thierry, DANG NGUYEN Godefroy, Interaction et coopération en réseau. Un modèle de gratuité, Revue économique, 2001, p. 57-76
2. Les données ouvertes
Les données ouvertes, ou open data, sont des données distribuées par des collectivités ou des États. Le principe est simple : rendre disponible, réutilisable et participatif des données publiques ayant un intérêt général. L’open data garantit le libre accès des données, sans aucune restriction (même commerciale). Les données proviennent souvent de capteurs avec une récupération automatisée vers une base de données accessible et normalisée. Tim Berners-Lee, le père du web, avait déjà introduit cette notion en 2006.
L’open data permet d’encourager les représentations innovantes et la création de connaissances de la part de tous. Nous pouvons citer le projet collaboratif de cartographie OpenStreetMap qui à l’aide des internautes s’enrichit en précision ou encore l’application web, Où recycler ?.
Avec les données ouvertes, nous faisons face à de grands volumes. Le big data ou mégadonnées désigne le fait de récolter massivement des données provenant d’internet. Ces données peuvent être utilisées pour de nombreux usages tels que le ciblage marketing/publicitaire mais aussi la détection des pannes dans un réseau. On réalise donc des dashboard pour déchiffrer des masses de données. L’utilisation de la datavisualisation permet de mettre en forme ces immenses données afin de les visualiser et de mieux les comprendre.
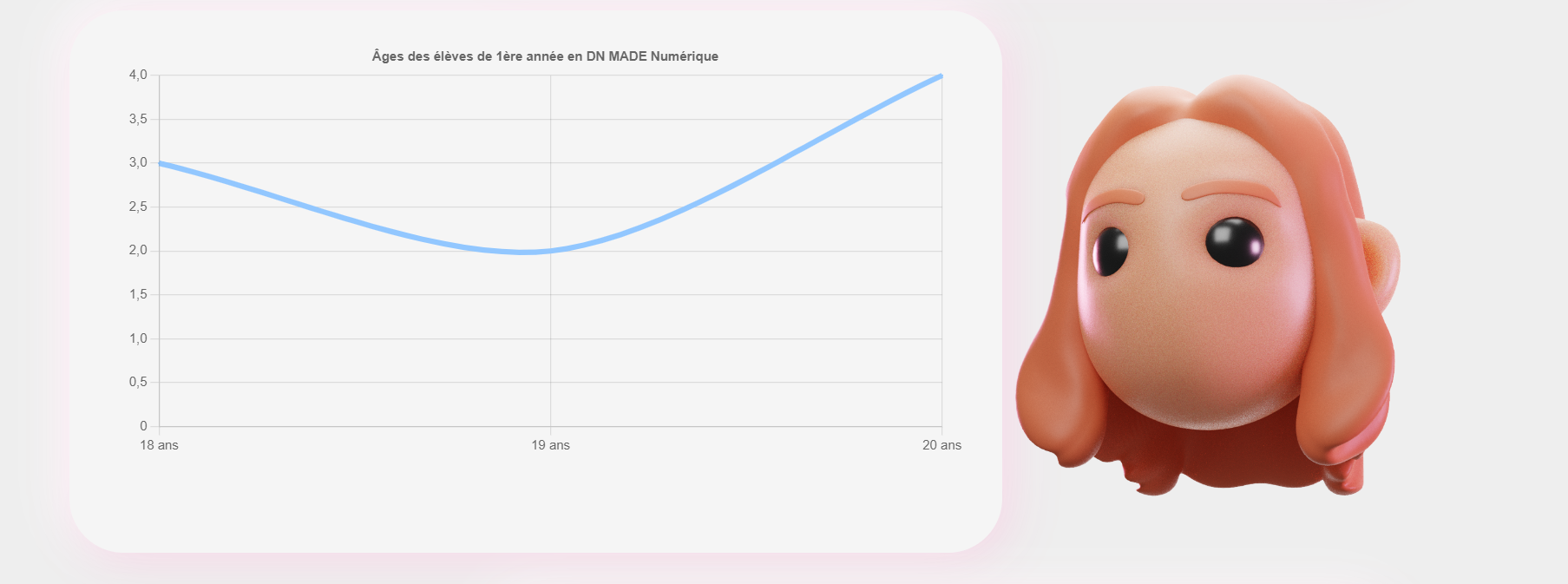
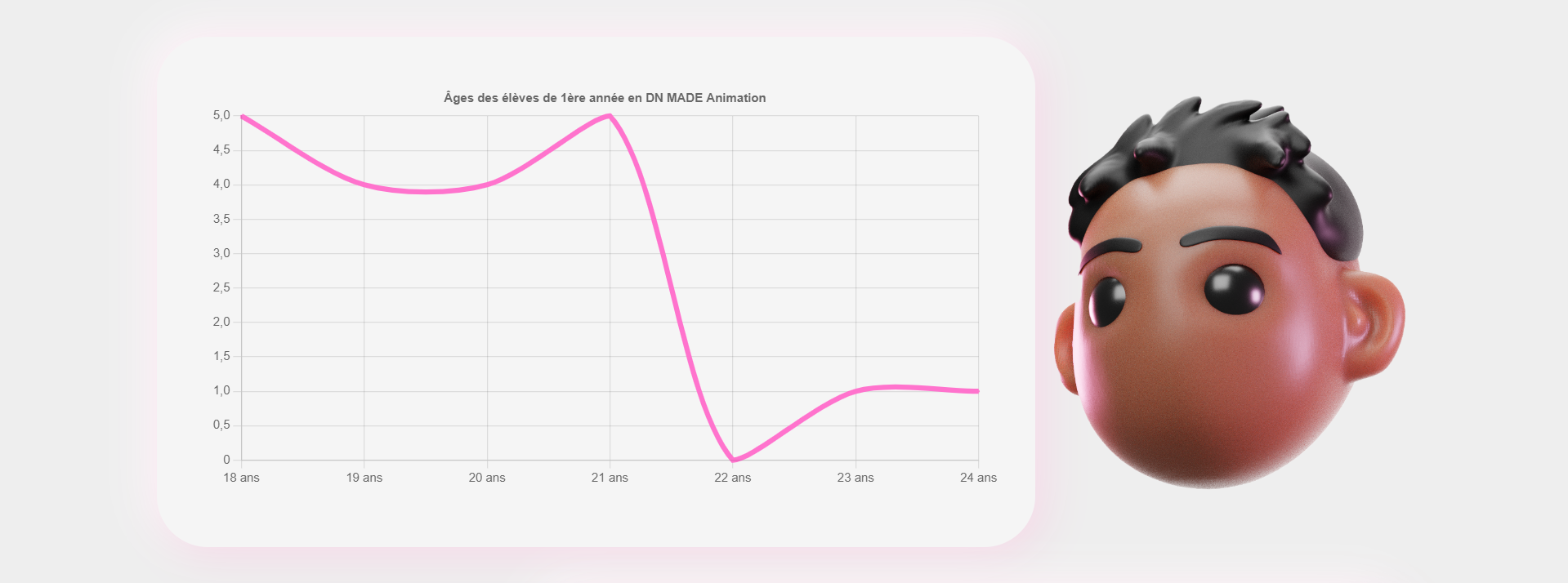
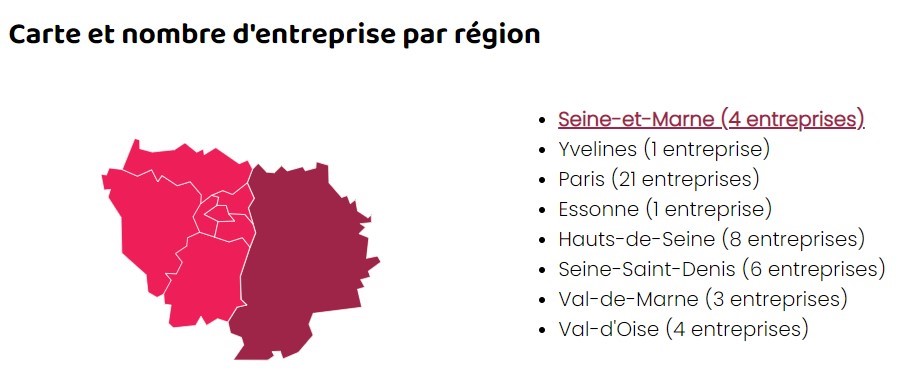
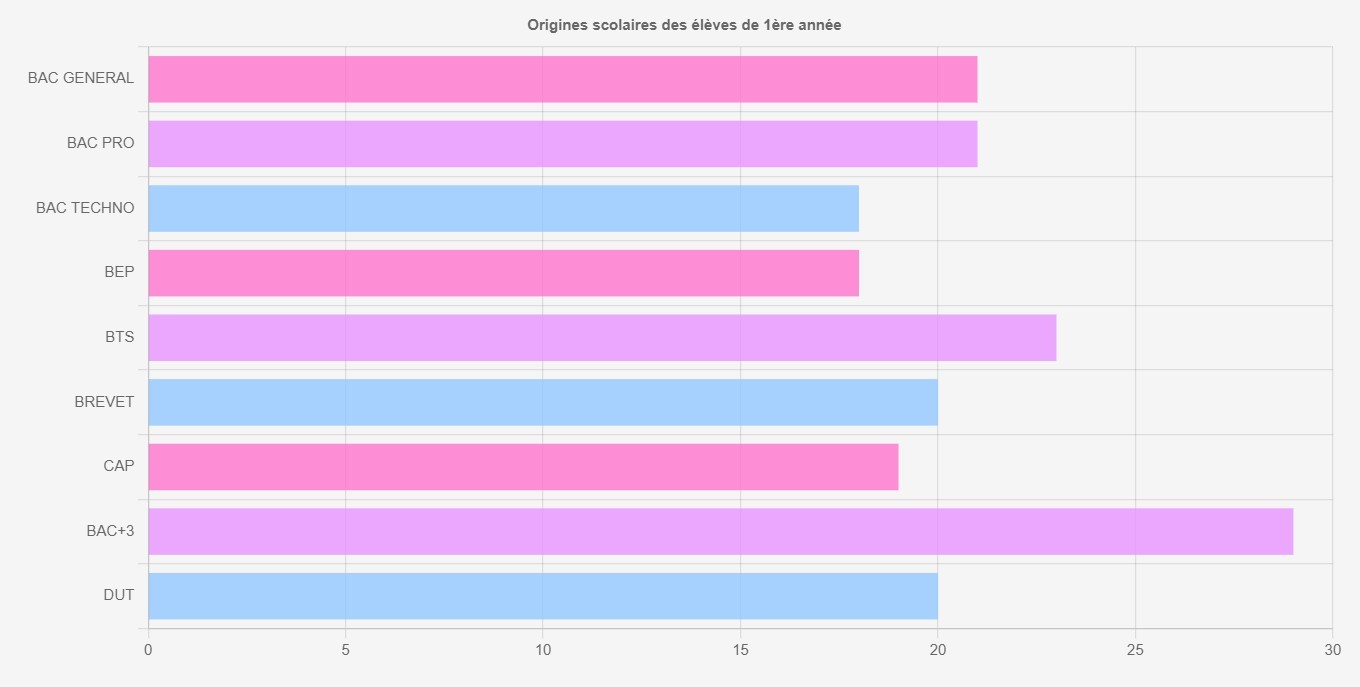
Comment toutes ces données peuvent-elles nous aider pédagogiquement au Campus ? L’open data est LA source de données pour la dataviz. Nos étudiants en DNMADe Numérique se questionnent sur les représentations visuelles possibles de ces données créées de manière électronique. Il s’agit également de leur sujet de micro-projet en fin de première année. Grâce aux différentes APIs publiques, ils développent des dataviz interactives avec des librairies JavaScript comme D3.js ou Chart.js. Voici un extrait de leurs travaux :
Les étudiants ont manipulé des données de notre établissement. Ils ont dû les mettre en forme visuellement pour faciliter la lecture.